
Meta AI Introduces BLT: Byte Latent Transformers
- Michael Gruner
- Dec 14, 2024
- 4 min read
Last December the 12th Meta AI presented an improvement to the current LLMs: Byte Latent Transformers. It replaces the current token approach by patches of bytes of dynamic sizes. Results show that BLTs reach LLM accuracy with increased inference performance.
Tokens, Tokenizers and LLMs
Unlike humans, current Large Language Models (LLMs) don't communicate at the word level. Researchers have found that, from a statistical point of view, there are ways to group characters that allow LLMs learn language patterns in a more efficient way than words do. These groups of characters are called tokens.
The very first stage of a LLM is to convert sentences into a sequence of tokens. Said otherwise: convert a sequence of words into a sequence of tokens. This conversion is performed by an initial algorithm called the Tokenizer. Similarly, the output of the LLM is a token (or sequence of tokens if you invoke the LLM repeatedly). This needs to be decoded to words that humans understand by using, again, the tokenizer.
While tokens allow the LLM to learn more efficiently, they are also the source of many limitations in these models. For example, GPT-2 was particularly bad at programming Python even when the language was well represented in the training set. The cause was found to be in the tokenizer not being able to represent popular character sequences in the language.
Tokenizers and their strengths and limitations fall out of the scope of this post. If you want an in depth technical walkthrough on tokenizers I recommend the video by the great Andrew Karpathy on the subject.
Tokens vs Entropy Sized Patches
The idea of the BLT is conceptually simple
and ingenious. Instead of grouping characters in tokens, which are fixed in size and composition, BLT segments the characters dynamically based on a set of rules. These groupings of dynamic sizes are called patches. Simply put: if the next character is very predictable, the character can be appended to the current patch. If, on the other hand, the character is unpredictable, a new patch is started for it. The technical term for this predictability is entropy. The higher the entropy, the less predictable
the next character is.
Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable
We can build a simple intuition on the why this brings an improvement. Imagine you speak your native language (english, for example) and you are learning a second one (spanish, for example). If I read a paragraph to you in english, you won't need to put much effort into understanding it, and can even predict the next word as I read it. On the other hand, you'll need to concentrate much harder to understand the paragraph I read to you in Spanish.
The concept in BLTs is similar: predictable characters are all grouped in larger patches and processed all at once. Unpredictable characters are processed in smaller patches, and hence need more LLM processing resources to "understand" them.
Here's an example on different "grouping" strategies, including the entropy based ones presented by Meta AI in BLTs:

The same sentence is split in different amount of groups. The more groups, the more processing the LLM needs to perform.
One last question remains: why don't we pass the full sentence in a single patch? As ambitious it may seem, unfortunately, by doing so we would lose a lot of low level understanding necessary to understand and produce language. The technical details of the "why" this happens are out of the scope of this post, but suffice to say that these patches are converted to embeddings: vector representations of the semantic meaning behind the patch. Regardless of the size
of the patch, the size of the embedding is the same. You probably can intuitively see how, if the group is too large, it all gets mashed up in a single meaning which affects the prediction capabilities. See our blog on Semantic Search for more information on embeddings.
The Byte Latent Transformer
At the risk of oversimplifying the proposal, the BLT architecture can be divided in three modules:
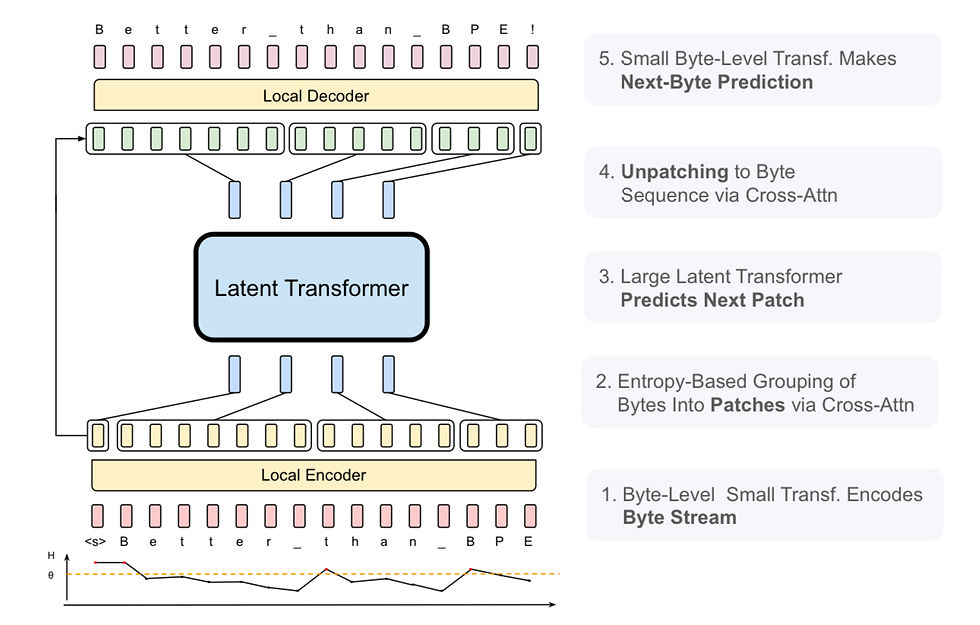
At the bottom we see the Local Encoder, which is in charged of converting the sequence of characters in a sequences of patches. This model is a small transformer that combines hash n-gram embeddings (introduced in the paper as well) along with multi-head cross attention. The result is a sequence of patches of different sizes where the processing is distributed accordingly.
Then we have the Global Latent Transformer. This is an autoregressive transformer that converts a sequence of input patches into a sequence of output patches. Imagine a language translation model: it takes a sequence of English words, which are compressed into a Latent Space. This latent space holds the "meaning" or "semantics" behind the sentences, which is a compressed representation. Then, it takes this "meaning" and converts it into a sequence of literal words in another language. This is similar in the Global Latent Transformer, an input sequence of patches is transformed into an output sequence of patches, except that this output sequence has no meaning for us humans.
Finally, the Local Decoder is a small transformer formed by multi-head cross-attention layers that convert a sequence of patches into a sequence of bytes. These are converted to words which we can understand.
Refer to their paper for a more detailed architecture explanation.
Did the LLM Landscape Just Change?
No. Not yet at least. Current tokenizer-based models have huge traction and they have been widely studied. The BLT is a successful proof of concept that needs to be scaled and adopted, and that is going to take a good while. Regardless, it's exciting to see some of the most evident problems of the current LLMs being solved.
Let's Talk!
Do you need help with your AI project? RidgeRun.ai offers expert consulting services for video, audio and natural language processing projects. Let's talk!
Comments